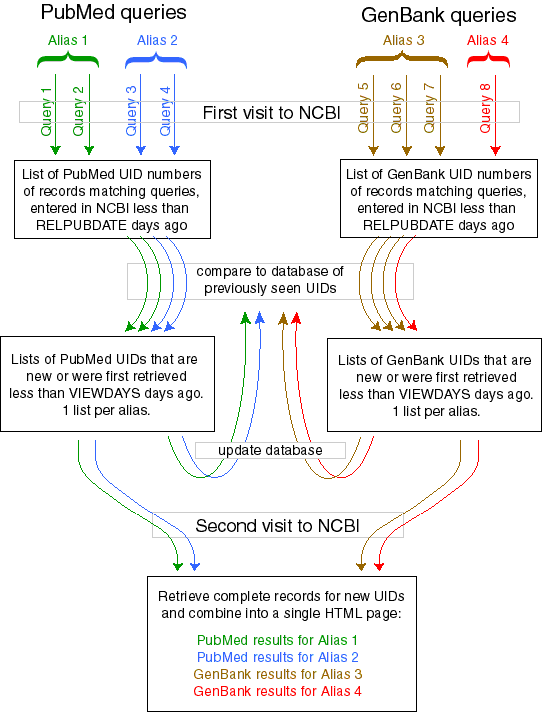
The first visit collects the UID (unique identifier) numbers of the database entries that match any of your queries, provided that their "date stamp" (the date they were added to the NCBI database) indicates that they are younger than the number of days specified by the variable RELPUBDATE (by default this is 100 days; you can change it on the command line or by editing the config file).
The UID lists are then compared to a database (containing both PubMed and GenBank UIDs). The database stores lists of UIDs and the calendar date that PubCrawler first found each UID (this date may be different from NCBI's date stamp, depending on how frequently you run PubCrawler). Interesting UIDs -- those that are new or are younger than the VIEWDAYS variable (specified on the command line or in the config file) -- are chosen for display.
If you use the same alias for multiple queries, the UIDs matching any of these queries are merged. This means that if the same UID is matched by several queries (within one alias) it will only appear once in the list of hits. If a UID is matched by queries with two different aliases, it will appear in both hit-lists.
The database is updated, and any UIDs that are older than RELPUBDATE are deleted (this prevents the databases from growing indefinitely).
A second visit is then made to NCBI to retrieve the complete
records for the new UIDs, and these are shown on the results page, grouped
alias-by-alias. If a lot of new records have been hit only the first
20 are shown for each alias, with HTML buttons for the rest (you can set
the number to display using the FULLMAX
variable in the config
file). The results for each alias also include HTML buttons that
allow you to retrieve the complete records for older entries (those that
are not new today, but are less than VIEWDAYS days old).